Extraction of the Fused Skeleton from one Microsoft Kinect and WIMUs
The Fusion method couples the advantages of the Microsoft Kinect sensor and the Wearable Inertial Measurement Units (WIMUs).
The key idea of this methodology is to apply the accurate rotational estimation from the WIMUs datasets to animate a 3D reference skeleton taken from a single frame of the Microsoft Kinect capturing device.
Applying only rotations to each segment of the reference skeleton is sufficient to animate it, and it overcomes some patent drawbacks of the Kinect sensors: occlusion, rapid movements, limited field of view, lighting influence and so on.
This method is designed for the Coach & Train scenario using 9 WIMUs, although the flexibility of the system allows the Fusion to be applied on specific parts of the body, i.e. reducing the number of sensors.
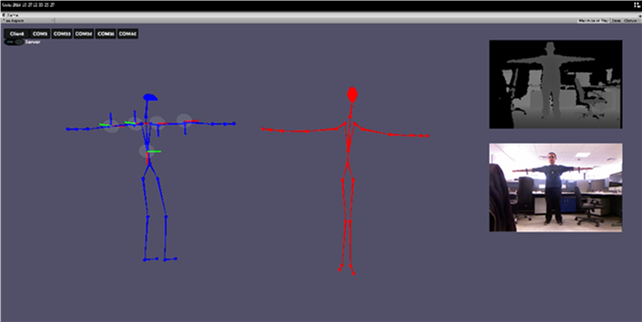
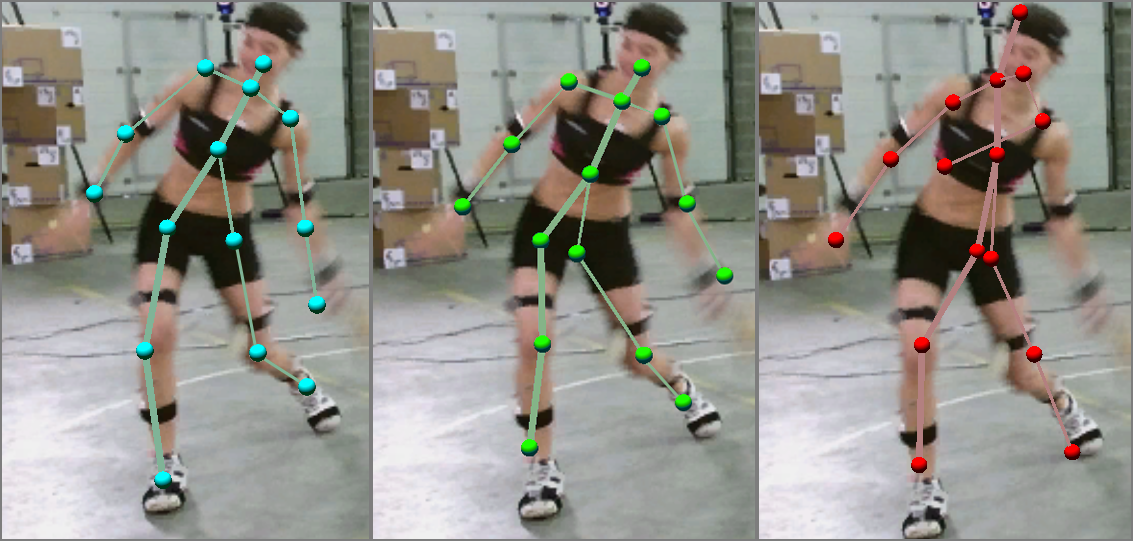
T pose on-the-fly automatic real time calibration (Blue: Fusion, Red: Kinect)

The fused skeleton using WIMUs (blue skeleton) can tackle the occlusion problem arising with the visual based Kinect system (red skeleton)
3D Sport Skills Motion Reconstruction from Video Legacy Content
The video-based motion capture approach allows to extract 3D athlete motion from video broadcast sources, providing an important tool for preserving the heritage represented by these movements, when only the video-legacy content is available.
Broadcast videos include camera motion, multiple player interaction, occlusions and noise, presenting significant challenges to solve the reconstruction.
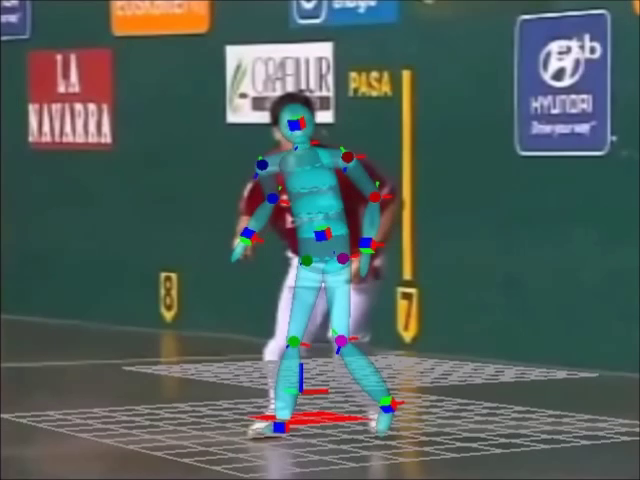
The approach requires an initial definition of some key-frames and setting of 2D key-points in those frames manually.
Thereafter an automatic process estimates the poses and the positions of the players in the key-frames, and in the frames between the key-frames, taking into account collisions with the environment and human kinetic constraints.
Experimental results show that our method obtains results comparable to state-of-the-art learning-based approaches in accuracy and performance but without the need of learning 2D-3D mapping models from training data.
This data could be used to analyze the sport's evolution over time, or even to generate animations for interactive applications.

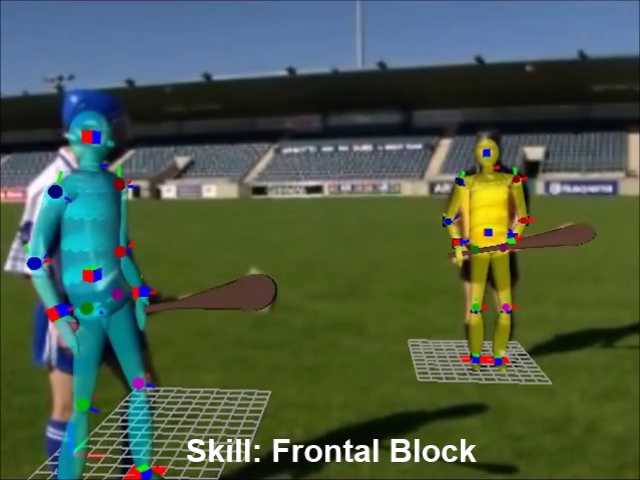

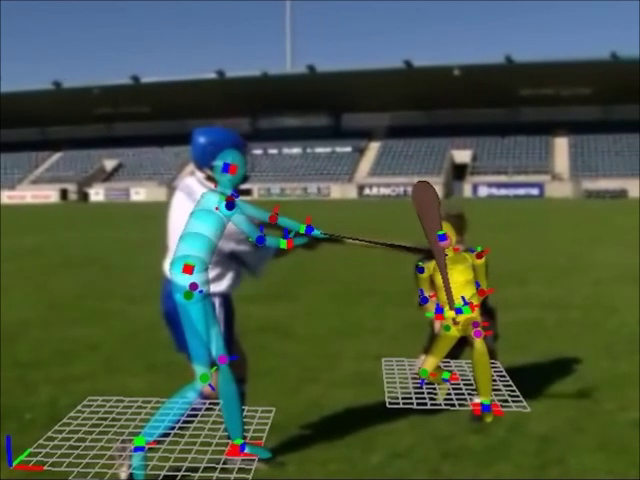



Full Body 3D Reconstruction
Aiming to preserve traditional sport heritage, dynamic 4D media of today’s professional athletic performances are needed.
Leveraging multiple pre-calibrated and synchronized consumer-grade Colour & Depth sensors (Microsoft Kinect) and real-time computer vision techniques, the sensor data are fused and then processed to provide a realistic 3D “replicant”.
This replicant allows for 360 free-view-point visualization and can be placed in any virtual environment.
Real-time full body 3D reconstruction of humans is a Tele-immersion enabling research domain, which can also be applied to other domains besides cultural heritage preservation like in the industries of entertainment, gaming, advertisement, broadcasting, health, learning etc.
Video links:
Full Body 3D Reconstruction Video 1
Full Body 3D Reconstruction Video 2
Pictures






Skeleton from Volume extracted from 4 Kinect Sensors
Skeleton from Volume is a fast method for human skeleton extraction and tracking from multiple raw depth data, exploiting the human volume information.
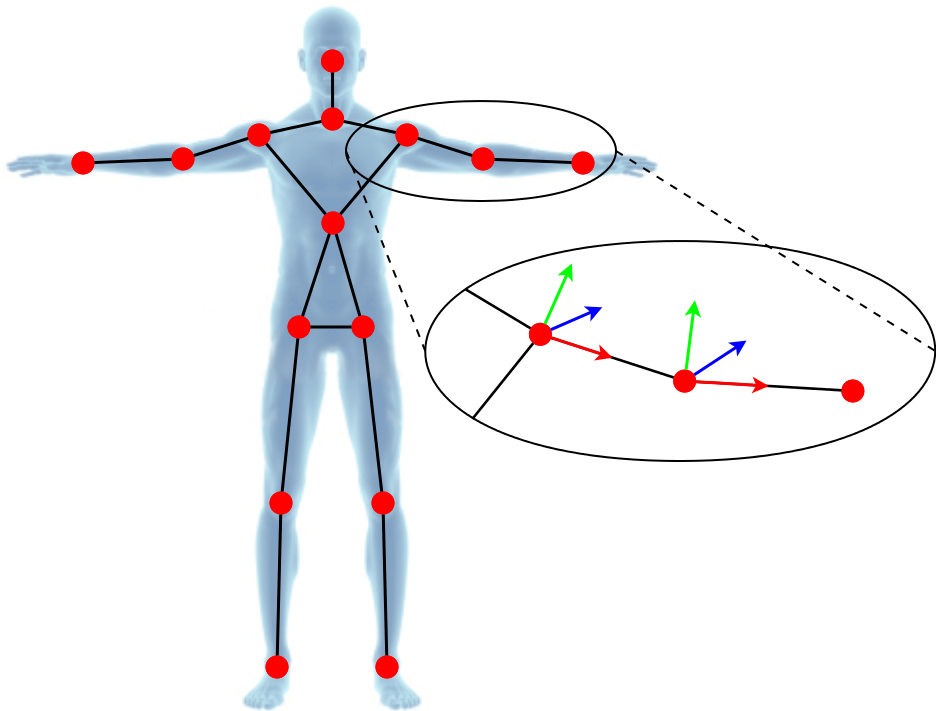
The proposed method tracks the joint positions of a 15-joints skeletal structure, which is separated into a) the rigid-body part that includes the “torso”, the “hips”, the “neck” and the “shoulders” and b) the limb parts that consist of the elbow- and wrist-joints or the knee and ankle-joints.
The skeleton extraction method consists of two phases.
Initially, during a “user-calibration” phase, the user body structure is estimated, including the detection of the rigid-body joints and the estimation of limb bones’ lengths.
Then, during the main skeleton-tracking phase, both the position-orientation of the rigid-body part and the limb-joint positions are tracked, while considering the voxels as nodes of a spatial graph enables us to utilize several graph techniques towards our objective.
Video link:
Skeleton from Volume extracted from 4 Kinect Sensors Video
Pictures